T9 stands for Text on 9 keys. It's the -patented- mobile phone technology that allows words in SMS messages to be entered by a single keypress for each letter. So instead of pressing the '3'-key three times to enter an 'f', you press the key only once. The software will then try to figure out whether you wanted a 'd', an 'e', or an 'f' by looking up your input in its dictionary and make an educated guess. T9 technology allows you to rapidly enter text on a numerical keypad, but also on a small touch panel like a smart phone or an iThing. Even on larger touch screens the technology is useful: it allows the input region for free text to be as small as possible. In a lot of applications, displaying a full touch keyboard would just take too much screen infrastructure.
Encoding: from clear text to T9
The text you enter via the key pad or touch screen will be encoded to the T9 format, and compared to the internal dictionary. That dictionary contains sentences, words, or fragments (n-grams). That dictionary is indexed by the T9-encoded version of the text value. So the encoding algorithm is called while you're inputting text, but also when building or updating the dictionary.
Text Normalization
The first step in T9-encoding is text normalization, which translates the input to the 26 characters of the alphabet. The only hard part here is removing the so-called diacritics, markers like
- accent: déjà becomes deja,
- cedilla: façade becomes facade, and
- diaeresis: Noël becomes Noel.
Fortunately there's a method in .NET that does this for us: the String.Normalize() method, with an overload that takes a Unicode normalization form as parameter. Here's a sample C# routine to remove the diacritics from an input string:
/// <summary>
/// Normalizes a string and removes diacritics.
/// </summary>
public string RemoveDiacritics(string clearText)
{
string normalizedText = clearText.Normalize(NormalizationForm.FormD);
StringBuilder sb = new StringBuilder();
foreach (char ch in normalizedText)
{
UnicodeCategory uc = CharUnicodeInfo.GetUnicodeCategory(ch);
if (uc != UnicodeCategory.NonSpacingMark)
{
sb.Append(ch);
}
}
return sb.ToString().Normalize(NormalizationForm.FormC);
}
Here's a screenshot from the included sample project:
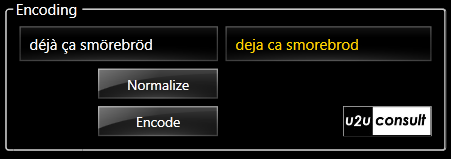
Text Encoding
Once the text is normalized to the 26 alphabetic characters, the rest of the encoding is a piece of cake: 'a', 'b' and 'c' will be mapped to '2' etc. We'll use a train of regular expressions to do this:
/// <summary>
/// Encodes a string to the T9 format.
/// </summary>
public string EncodeString(string clearText)
{
// Normalize and convert to lowercase.
string result = this.RemoveDiacritics(clearText).ToLower();
// Remove digits.
result = Regex.Replace(result, "[2-9]", string.Empty);
// Translate to SMS.
result = Regex.Replace(result, "[abc]", "2");
result = Regex.Replace(result, "[def]", "3");
result = Regex.Replace(result, "[ghi]", "4");
result = Regex.Replace(result, "[jkl]", "5");
result = Regex.Replace(result, "[mno]", "6");
result = Regex.Replace(result, "[pqrs]", "7");
result = Regex.Replace(result, "[tuv]", "8");
result = Regex.Replace(result, "[wxyz]", "9");
// Replace remaining non-SMS characters by word boundary.
result = Regex.Replace(result, "[^2-9]", " ");
return result;
}
Here's again a screenshot from the included demo application:
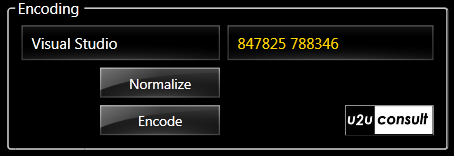
Using the dictionary
You can trigger the decoding of a single word when a word boundary character is entered (with the '1' button). The included sample program takes a simpler approach: it triggers the decoding algorithm when length of the input text reaches 4. This is because the internal dictionary is specialized in four-letter words (you know: the words your wife doesn't like you to use at home, like dust, wash, cook, and iron) . The included dictionary contains more than 600 four-letter words.
Text decoding
T9-encoding is not directly reversible: an encoded T9-string represents many alphanumerical strings. Most of these letter combinations will not be in your internal dictionary of known words or sentences. The decoding boils down to a lookup in the dictionary. Here's the source of the decoding method in the included sample project. The call may return 0, 1, or more candidates:
/// <summary>
/// Decodes a T9 string to a word in the dictionary.
/// </summary>
public List<string> DecodeString(string t9Text)
{
return (from w in this.dictionary
where w.Key == t9Text
select w.Value).ToList();
}
Here's the function in action:
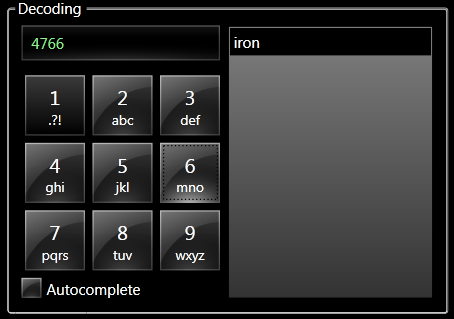
Text prediction
The real strenght in T9-ish technologies lies in the prediction capabilities. An engine able to auto-complete your input, will save you a lot of time. This is where you will need to strike a balance between speed and functionality. The larger the dictionary and the more flexibility you introduce (n-grams, fuzzy lookups using different edit distance algorithms, phonetic search), the slower the response time becomes. The included project has a simplistic prediction routine, based on the prefix. Again it returns a list, which may be empty:
/// <summary>
/// Predicts a T9 decoding, based on a prefix.
/// </summary>
public List<string> Predict(string prefix)
{
return (from w in this.dictionary
where w.Key.StartsWith(prefix)
select w.Value).ToList();
}
Here's a screenshot of it:
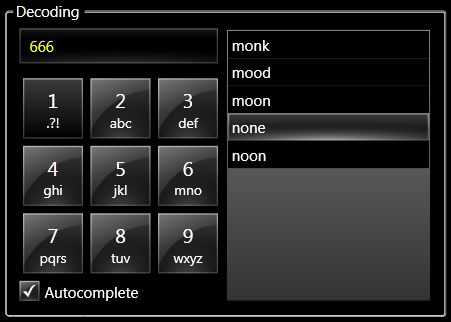
Source code
Here's the whole project. It's a nice little WPF MVVM application: U2UConsult.T9.Sample.zip (93,09 kb)
By the way, the app is not touch-enabled (they're real buttons ;-).
Enjoy!