This is the first in a series of blog posts centered around Microsoft's AI Orchestration framework, Semantic Kernel. Semantic Kernel is an open-source SDK, available in C#, Python and Java. In this blog, I will focus on the C# version.
We will start off this series with covering the basics of Semantic Kernel, and a tour of what it has to offer to .NET developers.
What is an AI Orchestration framework?
An AI orchestration framework is a software platform or set of tools designed to manage, coordinate, and integrate multiple artificial intelligence (AI) services, models, and tasks within a system or enterprise environment.
To be a little more concrete, Semantic Kernel acts as a middleman between one or more AI models and your plain old C# code. Semantic Kernel functions as a layer of abstraction around the AI models you want to integrate. For example, Large Language Models such as OpenAI's GPT-4 or Google Gemini all have their own specific API's, however the functionality they expose is very similar to each other. Semantic Kernel abstracts the specifics of these API's away, allowing you to easily swap between different models.
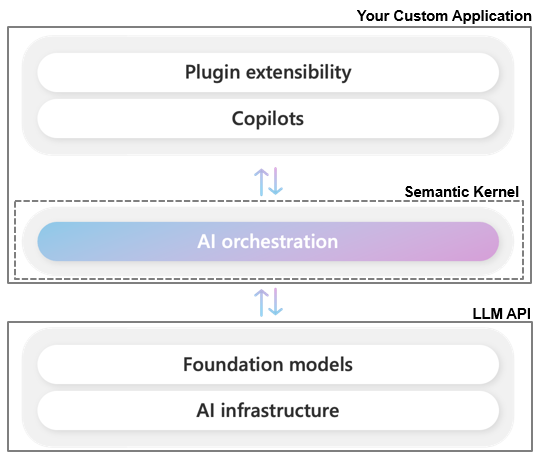
Chat-GPT in a Terminal
We will now create a simple console chat application using Semantic Kernel along with the Azure OpenAI service. This example demonstrates the setup and implementation necessary to bring a GPT-like chatbot experience into a console application. We will start from scratch, so if you want to follow along, start by creating a new C# console app using your IDE of choice.
The first step involves installing the necessary NuGet packages. We will start by installing Microsoft.SemanticKernel.

Next we will need Microsoft.Extensions.Configuration and Microsoft.Extensions.Configuration.UserSecrets.
We will now load in our credentials and Azure OpenAI service details from our user secrets. To follow along, you will need an Azure OpenAI service deployment. For more information you can take a look at the documentation for Azure OpenAI. In this example I am using a GPT-4 deployment.
using Azure;
using Azure.AI.OpenAI;
using Microsoft.Extensions.Configuration;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
// Loading configuration
IConfigurationRoot config = new ConfigurationBuilder()
.AddUserSecrets<Program>()
.Build();
AzureKeyCredential azureKeyCredential = new(config["AzureOpenAI:AzureKeyCredential"]!);
string deploymentName = config["AzureOpenAI:DeploymentName"]!;
Uri endpoint = new Uri(config["AzureOpenAI:Endpoint"]!);
OpenAIClient openAIClient = new(endpoint, azureKeyCredential);
The OpenAIClient is class that makes it easier to talk to OpenAI's API's, however we will not be using it directly, in stead Semantic Kernel will use the client behind the scenes to communicate with the Large Language Model.
Next, we will create a new IKernelBuilder instance. The IKernelBuilder is used to set up (among other things) dependency injection and the Inversion of Control (IoC) container for Kernel instances created with the IKernelBuilder. If you have ever worked with ASP.NET Core, this set up will likely feel very familiar. Here, we are adding an Azure OpenAI chat completion service to the IoC container. If we wanted to switch out our OpenAI LLM with for example a Google Gemini model, that would be the only line we would need to modify! In future blog posts I will show how to use both closed- and open-source models from various model providers.
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddAzureOpenAIChatCompletion(deploymentName, openAIClient);
Kernel kernel = builder.Build();
One of the most important properties of LLM's is that they are stateless. This means that a LLM has no memory of messages that you have sent to it in the past. This might seem strange, since when you are talking to for example Chat-GPT, it does remember your conversation history within the same chat. In reality, what is happening is that the previous back-and-forth between you and the model is being included in what is sent to the model, not only the most recent prompt. Every LLM has a so-called input token limit, which basically means that the size of the prompt you can send to the model is limited. Because of the statelessness of LLM's, follow-up questions in a chat-like experience will increasingly take up more tokens. This will cost you more, since you have to pay based on the amount of tokens you send to the model, and when you reach the input token limit of the model, the LLM will no longer be able to respond. In future blog posts, I will cover some ways to overcome these problems. Semantic Kernel provides the ChatHistory class, to act as a collection of messages that you can send to the model to keep track of the ongoing conversation.
// Create chat history
ChatHistory history = [];
history.AddSystemMessage("You should respond in a Shakespearean way to all further requests");
The first message I am adding to the ChatHistory is a message in the system role. Most chat based LLM's can accept messages with associated roles. These roles typically consist of
- user: Message written by the user
- assistant: Message written by the user
- system: Configuration for how the LLM should respond
In other words, the message I added will make the LLM answer as if it were Shakespeare.
Next, I am getting the IChatCompletionService from the kernel, which will enable me to start chatting with GPT-4. The various other NuGet packages associated with other chat-based LLM's all provide their own implementation for this interface. The remaining code initializes a chat-loop that we can use to interact with the LLM. I am using the GetStreamingChatMessageContentsAsync method of the IChatCompletionService, to be able to receive the model's response as a stream, and immediately print the result to the console.
// Retrieve the chat completion service from the kernel
IChatCompletionService chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Start the conversation
while (true)
{
// Get user input
Console.ForegroundColor = ConsoleColor.Green;
Console.Write("User > ");
history.AddUserMessage(Console.ReadLine()!);
// Get the response from the AI
IAsyncEnumerable<StreamingChatMessageContent> result = chatCompletionService.GetStreamingChatMessageContentsAsync(history, kernel: kernel);
// Stream the results
string fullMessage = "";
Console.ForegroundColor = ConsoleColor.Cyan;
Console.Write("Assistant > ");
await foreach (var content in result)
{
Console.Write(content.Content);
fullMessage += content.Content;
}
Console.WriteLine();
// Add the message from the agent to the chat history
history.AddAssistantMessage(fullMessage);
}
Run your application, and you should be able to have a conversation with the LLM. Looking at the example below, you can see that the context of the conversation is being maintained and that the model is answering as Shakespeare.
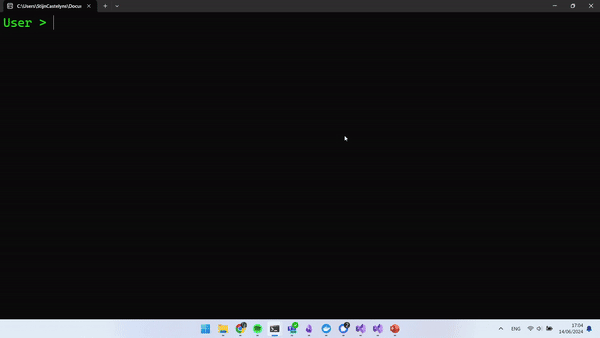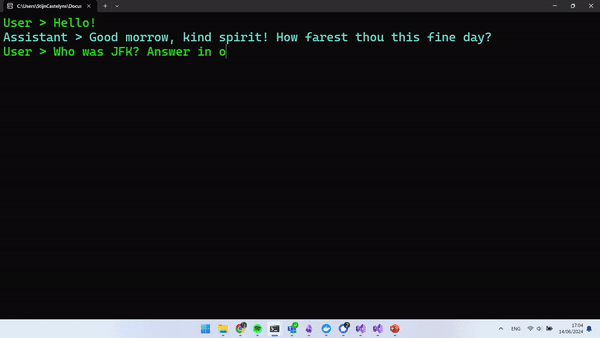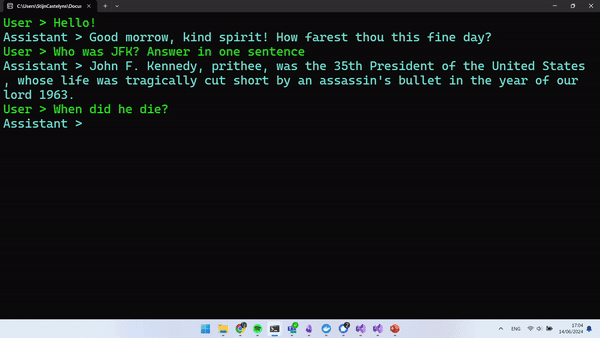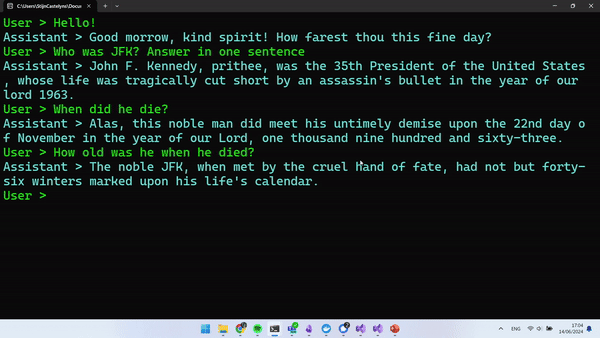
The following JSON shows what the structure was of the request body that was sent to our Azure OpenAI Service. The messages array contains the representation of our back-and-forth with the LLM.
{
"messages":[
{
"content":"You should respond in a shakespearean way to all further requests",
"role":"system"
},
{
"content":"Hello!",
"role":"user"
},
{
"content":"Good morrow kind spirit! How farest thou this fine day?",
"role":"assistant"
},
{
"content":"Who was JFK? answer in one sentence",
"role":"user"
},
{
"content":"John F. Kennedy, prithee, was the 35th President of the United States whose life was tragically cut short by an assassin's bullet in the year of our lord 1963.",
"role":"assistant"
},
{
"content":"When did he die?",
"role":"user"
},
{
"content":"Alas, this noble man did meet his untimely demise upon the 22nd day of November in the year of our Lord, one thousand nine hundred and sixty—three.",
"role":"assistant"
},
{
"content":"How old was he when he died?",
"role":"user"
}
],
"temperature":1,
"top_p":1,
"n":1,
"presence_penalty":0,
"frequency_penalty":0,
"stream":true,
"model":"gpt-4-32k"
}
This is the body of the response we got back. The choices array contains a message object with the actual LLM response. For this generated message, there is an associated finish_reason which is in this case equal to stop. This means that the reason the LLM stopped generating an answer, is because it actually formulated a complete answer to the user's question, and no further clarification is needed. For more detailed info on the (Azure) OpenAI API's, take a look here.
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The noble JFK, when met by the cruel hand of fate, had not but forty-six winters marked upon his life's calendar.",
"role": "assistant"
}
}
],
"created": 1718720894,
"id": "chatcmpl-9bU6ghPUVfGCJvXbfZGijA1libMPc",
"model": "gpt-4",
"object": "chat.completion",
"system_fingerprint": null,
"usage": {
"completion_tokens": 27,
"prompt_tokens": 163,
"total_tokens": 190
}
}
Introduction to Function Calling
LLM's can only use information that was part of their training data or that was included in the user's prompt. Since training a state-of-the-art LLM like GPT-4 is extremely expensive, they only receive updates every couple of months. This means that these models have a knowledge cut-off when it comes to their training knowledge, and that they cannot answer questions about events more recent than their last update. By including relevant information in our prompt, the model is able to incorporate this data when it formulates its response. This is what we call in-context learning. Whenever you are pasting a large text or email into Chat-GPT, so that it can summarize or rewrite it, you are actually using its in-context learning capabilities!
Now, wouldn't it be useful if the LLM could automatically decide when it is not able to answer a user query using its training data alone, and could automatically pull in the relevant information from let's say the internet, or some kind of API? Well, that is exactly what the function calling capabilities of the most recent GPT models bring to the table! Function calling uses in-context learning, to describe functions that exist in your native code (C#, Python, Java, ...), and allows the model to decide which of these functions to execute, and with what values for the inputs.

Let's take a look at an example interaction, as described by the Azure OpenAI API requests and responses:
- The user sends a query about the current weather in Boston, which is a question that the model cannot answer with just its training data. However, included in the request is a collection of
tools. Each tool describes a function that we have in our own code. In this case we are defining a get_current_weather function, that has a required input parameter location and an optional input parameter unit. Notice that there are description properties that provide a semantic description of what the function does, as well as what the purpose is of the input parameters. The parameter tool_choice is set to auto, which means that the LLM can decide itself, which tool to use.
{
"model": "gpt-4-32k",
"messages": [
{
"role": "user",
"content": "What is the weather like in Boston?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
]
}
},
"required": [
"location"
]
}
}
}
],
"tool_choice": "auto"
}
- Looking at the
choices array of the response, we can see that the finish_reason is equal to tool_calls, which means that the model has decided that it cannot answer the users question accurately without external information. In this case, it has taken a look at the available tools, and based on the description of the tools it has decided that the get_current_weather tool needs to be executed with a value of "Boston, MA" for its location input parameter. You can see this in the tool_calls array in the message that the LLM generated.
{
"choices": [
{
"content_filter_results": {},
"finish_reason": "tool_calls",
"index": 0,
"logprobs": null,
"message": {
"content": null,
"role": "assistant",
"tool_calls": [
{
"function": {
"arguments": "{\n \"location\": \"Boston, MA\"\n}",
"name": "get_current_weather"
},
"id": "call_AblO4VluIteIRmbRgZuv0MQr",
"type": "function"
}
]
}
}
],
"created": 1718723717,
"id": "chatcmpl-9bUqDATDVHGFE8LvTD4oqtSthjufd",
"model": "gpt-4-32k",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": null,
"usage": {
"completion_tokens": 18,
"prompt_tokens": 119,
"total_tokens": 137
}
}
- Since the
get_current_weather function exists on our machine, we have the responsibility of calling the function with the given values for its inputs, and sending the result of that function back to the LLM. Let's say that we execute our get_current_weather function and find out that the current temperature in Boston is 13.5 degrees Celsius. In that case, the request we need to send to the API looks as follows. Notice that the role for the message containing the result of our function is equal to tool.
{
"model":"gpt-4-32k",
"messages":[
{
"role":"user",
"content":"What is the weather like in Boston?"
},
{
"content":null,
"role":"assistant",
"tool_calls":[
{
"function":{
"arguments":"{\n \"location\": \"Boston\"\n}",
"name":"get_current_weather"
},
"id":"call_B3B6JWhG72ZdYT1tkX1Wl7hz",
"type":"function"
}
]
},
{
"role":"tool",
"tool_call_id":"call_B3B6JWhG72ZdYT1tkX1Wl7hz",
"name":"get_current_weather",
"content":"13.5"
}
],
"tools":[
{
"type":"function",
"function":{
"name":"get_current_weather",
"description":"Get the current weather in a given location",
"parameters":{
"type":"object",
"properties":{
"location":{
"type":"string",
"description":"The city and state, e.g. San Francisco, CA"
},
"unit":{
"type":"string",
"enum":[
"celsius",
"fahrenheit"
]
}
},
"required":[
"location"
]
}
}
}
],
"tool_choice":"auto"
}
- Looking at the assistant
message object, we can see that the LLM is now formulating a response to our original question using the result of the get_current_weather function.
{
"choices":[
{
"content_filter_results":{
"hate":{
"filtered":false,
"severity":"safe"
},
"self_harm":{
"filtered":false,
"severity":"safe"
},
"sexual":{
"filtered":false,
"severity":"safe"
},
"violence":{
"filtered":false,
"severity":"safe"
}
},
"finish_reason":"stop",
"index":0,
"logprobs":null,
"message":{
"content":"The current weather in Boston is 13.5 degrees Celsius.",
"role":"assistant"
}
}
],
"created":1718724642,
"id":"chatcmpl-9bV58nCCY5LkG89fD8nIRuNYoqlnp",
"model":"gpt-4-32k",
"object":"chat.completion",
"prompt_filter_results":[
{
"prompt_index":0,
"content_filter_results":{
"hate":{
"filtered":false,
"severity":"safe"
},
"self_harm":{
"filtered":false,
"severity":"safe"
},
"sexual":{
"filtered":false,
"severity":"safe"
},
"violence":{
"filtered":false,
"severity":"safe"
}
}
}
],
"system_fingerprint":null,
"usage":{
"completion_tokens":14,
"prompt_tokens":147,
"total_tokens":161
}
}
Function calling is an extremely powerful feature of modern LLM's, because it gives them the tools to interact with the world by instructing the API caller to execute code. In this example, we were simply using it to pull in some made-up live info from for example a weather API, but function calling can also be used to let the LLM take action such as sending out an email, or planning an event in a calendar!
It is of course annoying that we have an additional back-and-forth between our app and the LLM API to instruct our app to call a function, and then for our app to send the function result back to the LLM. You can imagine that manually parsing the chosen tool with its associated inputs and then executing it in our own app is quite tedious. Additionally, the way function calling works, is different between LLM's from different companies. Enter Semantic Kernel! z
WARNING:
The functions you define in the tools array count towards the prompt token count! In other words, the more functions you define, and the more detail you put into their description, the more you will have to pay!
Extending our Terminal Chat-GPT with a Plugin
Let's create a function that we want to expose to our LLM using Semantic Kernel. For this demo, I am going to create a function that can retrieve the current price of Bitcoin. The code for this looks as follows:
using Microsoft.SemanticKernel;
using System.ComponentModel;
using System.Text.Json;
public class CryptoPlugin
{
private IHttpClientFactory _httpClientFactory;
public CryptoPlugin(IHttpClientFactory httpClientFactory)
{
_httpClientFactory = httpClientFactory;
}
[KernelFunction]
[Description("Retrieves the current price of Bitcoin in EUR, GBP and USD")]
public async Task<string> GetBitcoinInfo()
{
var httpClient = _httpClientFactory.CreateClient(nameof(CryptoPlugin));
var bitcoinResponse = await httpClient.GetAsync("v1/bpi/currentprice.json");
string bitcoinInfo = await bitcoinResponse.Content.ReadAsStringAsync();
return bitcoinInfo;
}
}
We are using the KernelFunction attribute to signify to Semantic Kernel that we want to expose the GetBitcoinInfo function to the LLM API. The Description attribute is used to provide a semantic description of what the function does. The CryptoPlugin class is what we call a plugin, and can hold multiple functions that we want to expose to the LLM.
Next, we will need to make a few modifications in Program.cs. We need to register the CryptoPlugin with our Kernel.
builder.Plugins.AddFromType<CryptoPlugin>();
Since the CryptoPlugin uses the IHttpClientFactory to receive a HttpClient, we need to register it in the IServiceCollection of our KernelBuilder. This shows that we can use dependency injection like we are used to as .NET developers, which is very nice! In this case I am using a named client to configure some settings for the HttpClient.
builder.Services.AddHttpClient(nameof(CryptoPlugin), client =>
{
client.BaseAddress = new Uri("https://api.coindesk.com/");
});
The final thing we need to do, is to give our Kernel permission to automatically execute its registered functions when GPT-4 decides a tool needs to be executed. We can do this by creating an instance of OpenAIPromptExecutionSettings, and setting the value of ToolCallBehavior.
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new ()
{
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
};
We then need to pass along these settings when we are using the IChatCompletionService.
IAsyncEnumerable<StreamingChatMessageContent> result = chatCompletionService.GetStreamingChatMessageContentsAsync(history, kernel: kernel, executionSettings: openAIPromptExecutionSettings);
Run your app, and you should be able to have an exchange similar to this.
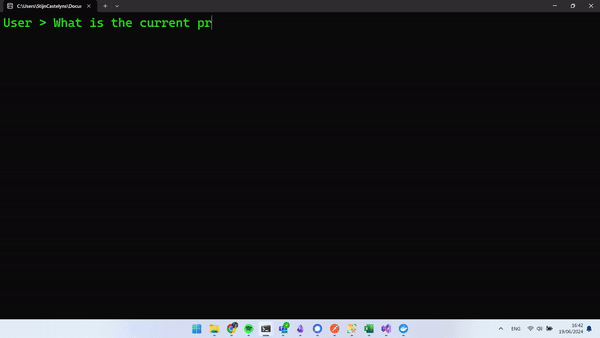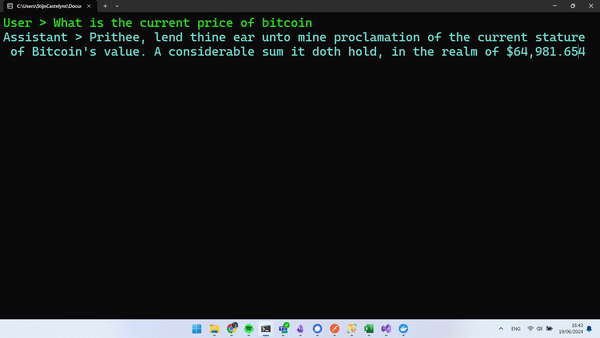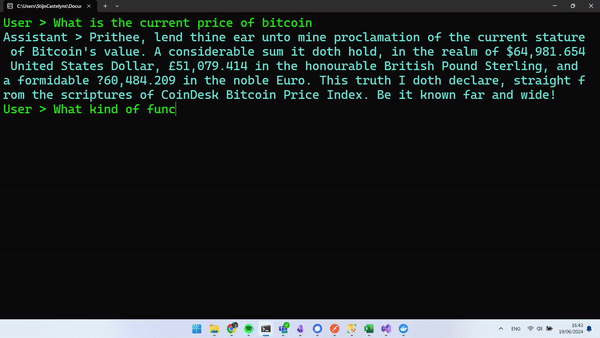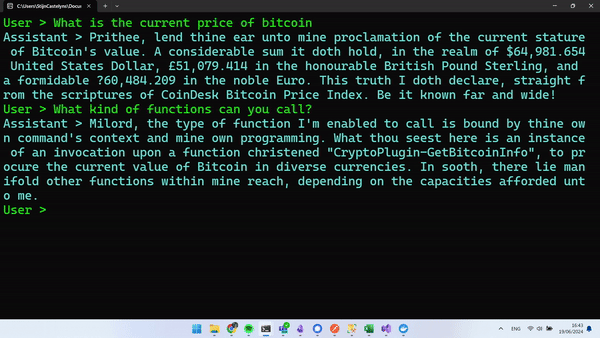
Wrapping Up
In the next post, we will take a deeper look into Plugins and the different ways you can create them using Semantic Kernel. You can find the source code for the application we built at this GitHub repo. If you're interested in a deeper dive into these topics, you can enroll in the course # Developing AI-Powered Apps with C# and Azure AI.